人形机器人估值狂飙 390 亿美元,但闷声发财的是这群「卖铲人」
一、一个反常识的开场:机器人还没赚钱,数据已经先赚了
先看两组扎眼的数字。
一边是本体的估值狂欢。美国 Figure AI 在 2025 年 9 月完成超 10 亿美元 C 轮,投后估值飙至 390 亿美元,比 18 个月前暴涨约 15 倍;Skild AI 在 2026 年 1 月由软银领投约 14 亿美元,估值超 140 亿美元,七个月翻了三倍;Physical Intelligence 则被传正洽谈约 10 亿美元新融资、估值或超 110 亿美元。中国这边同样火热:银河通用 2026 年 3 月完成 25 亿元新一轮融资,估值约 225 亿元,为国内估值最高的未上市具身公司;宇树科技 6 月 1 日科创板过会,对应发行市值约 420 亿元。
另一边却是冰冷的现实:本体公司几乎都还没真正赚到钱。优必选连年亏损,多数公司净利率微薄甚至为负。机器人卖出去了,钱却没落进口袋。
那么,谁先赚到了钱?答案是——卖数据的人。
具身数据独角兽光轮智能,2026 年一季度的单季收入据称已超过 2025 年全年总和;智元旗下的数据平台公司觅蜂科技,由红杉中国领投完成数亿元融资。觅蜂 CEO 姚卯青一语道破天机:"在具身智能尚未真正大规模商业化之前,数据作为基础设施,会比终端应用更早形成商业回报。"
这不是新鲜剧本。AI 圈向来有一条铁律:淘金热里最先稳定赚钱的,永远是卖铲子、卖牛仔裤的人。如今,具身智能正在重演这一幕。
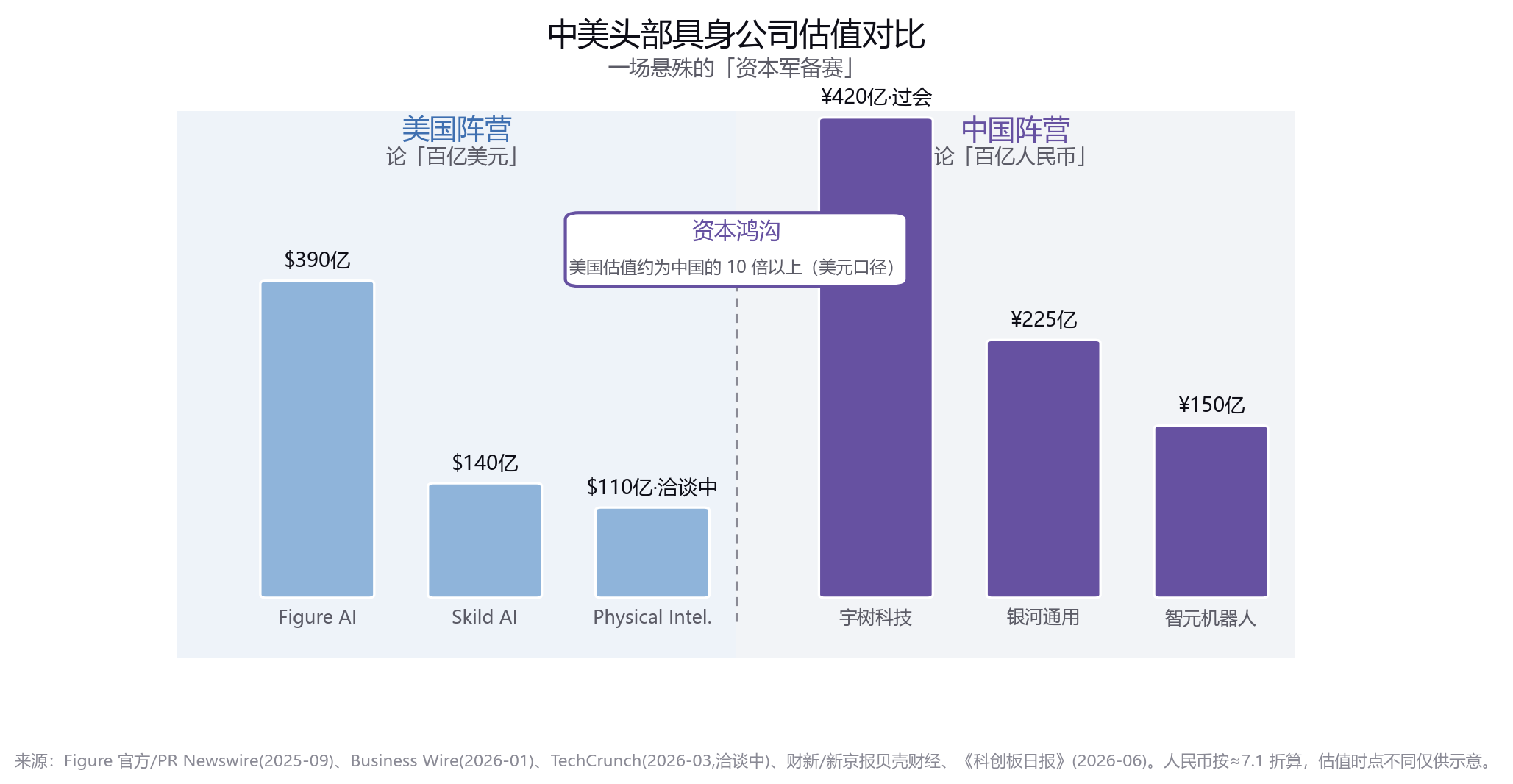
值得玩味的是这张估值对比图背后的结构性差异:美国头部公司论"百亿美元",中国头部公司论"百亿人民币"。换算成美元,中国估值最高的玩家也不过二三十亿美元量级,而 Figure 一家就近 400 亿美元。资本量级的鸿沟,恰恰逼出了中国"用工程效率和数据规模弥补资本差距"的另类打法——这是后文要讲的中美分野的伏笔。
二、数据为什么先赚钱:稀缺、刚需、资本外溢
数据生意能够抢跑,背后有三层逻辑。
第一层,极端稀缺,而且是结构性的稀缺。
截至 2026 年初,全球高质量真实物理交互数据的总量,据澎湃科技的行业测算仅约50 万小时——不足大语言模型训练语料的两万分之一。这是什么概念?如果说训练 GPT 的文本数据是一片海洋,那么今天全行业能用来训练机器人的真实数据,不过是一只水桶。
更棘手的是"数据跟着本体走":不同品牌机器人的传感器布局、控制模态各不相同,遥操作采来的数据高度绑定特定硬件,很难跨本体复用。这意味着稀缺不是暂时的供给不足,而是结构性的复用困境。
第二层,刚性需求,且在指数级膨胀。
当机器人从实验室走向工厂、物流、商超,数据需求从"实验室级"陡然跃升到"部署级"。光轮智能联合创始人杨海波称,2026 年的数据需求"百倍于去年"——单一任务训练就需千小时级数据,复杂任务更多。需求曲线陡峭上扬,供给却卡在水桶大小,价格信号自然清晰。
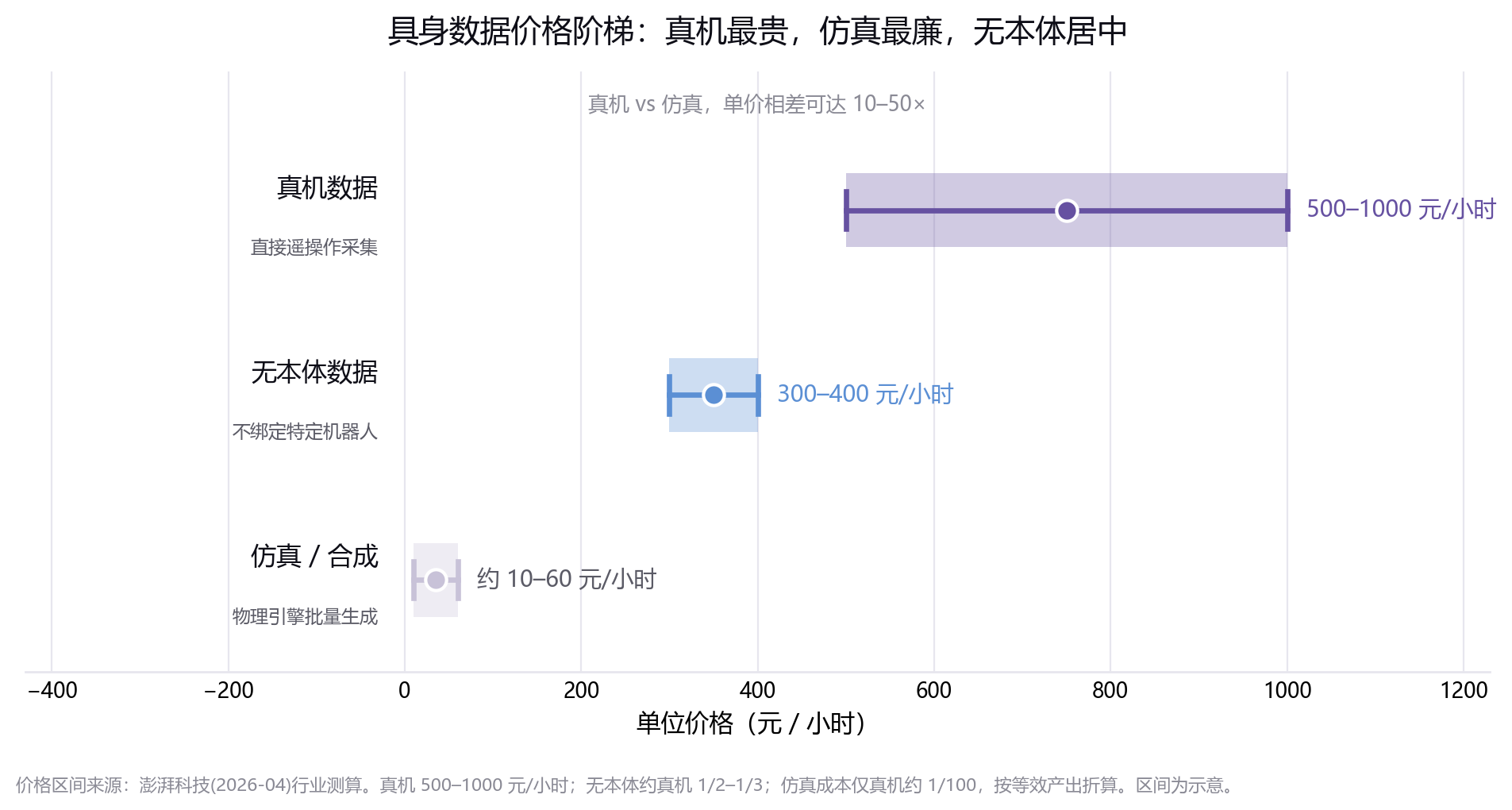
据澎湃科技,具身数据当前总体定价 200–500 元/小时;其中真机数据最贵,达 500–1000 元/小时;不依赖特定机器人的"无本体数据"价格约为真机的二分之一到三分之一。
第三层,资本外溢。
本体赛道的投资门槛被推高后,挤不进牌桌的资金转向商业化确定性更强的上游。一位投资人对媒体直言:"上游在商业化可预测性方面比机器人本体还要稳当——押注的不是某一家公司能不能活下来,而是整个行业对数据的刚需。"
换句话说,赌本体是赌"谁能赢",赌数据是赌"这场仗一定要打"。后者的确定性,显然更高。
三、技术底座:VLA 与世界模型,把数据"吃"进模型
数据之所以成为战略筹码,是因为新一代具身"大脑"对数据的胃口空前。
VLA(视觉-语言-动作)模型成为主流范式。 Physical Intelligence 的 π 系列是标杆:π0(2024 年)是首个通用机器人基础模型,π0.5 实现开放世界泛化,π0.6 已能在旧金山一家洗衣店稳定叠衣服商用。Google DeepMind 的 Gemini Robotics(2025 年 3 月)把物理动作变成模型的新输出模态;其 1.5 版本(2025 年 9 月)升级为多本体 VLA,可跨机器人迁移技能。
世界模型成为新前沿。 DeepMind 的 Genie 3(2025 年 8 月)能由一句文本实时生成 720p、24fps、可交互数分钟的虚拟世界,被视为破解数据瓶颈的钥匙。而就在 2026 年的 NVIDIA 技术盛会上,黄仁勋明确抛出一个判断:仅靠真实世界数据,不足以训练物理 AI——因为现实世界的复杂度与长尾边缘场景太多。NVIDIA 的解法,是把自己的算力转化为稀缺的数据原料:其合成运动生成管线,11 小时即可生成 78 万条合成轨迹,相当于约 6500 小时、九个月的人类演示数据;合成数据与真机数据结合,可将 GR00T 模型性能提升约 40%。
关键在于:无论架构如何演进,这些模型都必须用海量、高质量、可迭代的数据来"喂养"。模型越强,对数据的质量与多样性要求越苛刻。这正是数据成为战略咽喉的根本原因。
四、中美分野:两条路径,两种死穴
这是本文的核心判断:中美正走向两条截然不同的具身数据供给路径,而且各有致命弱点。
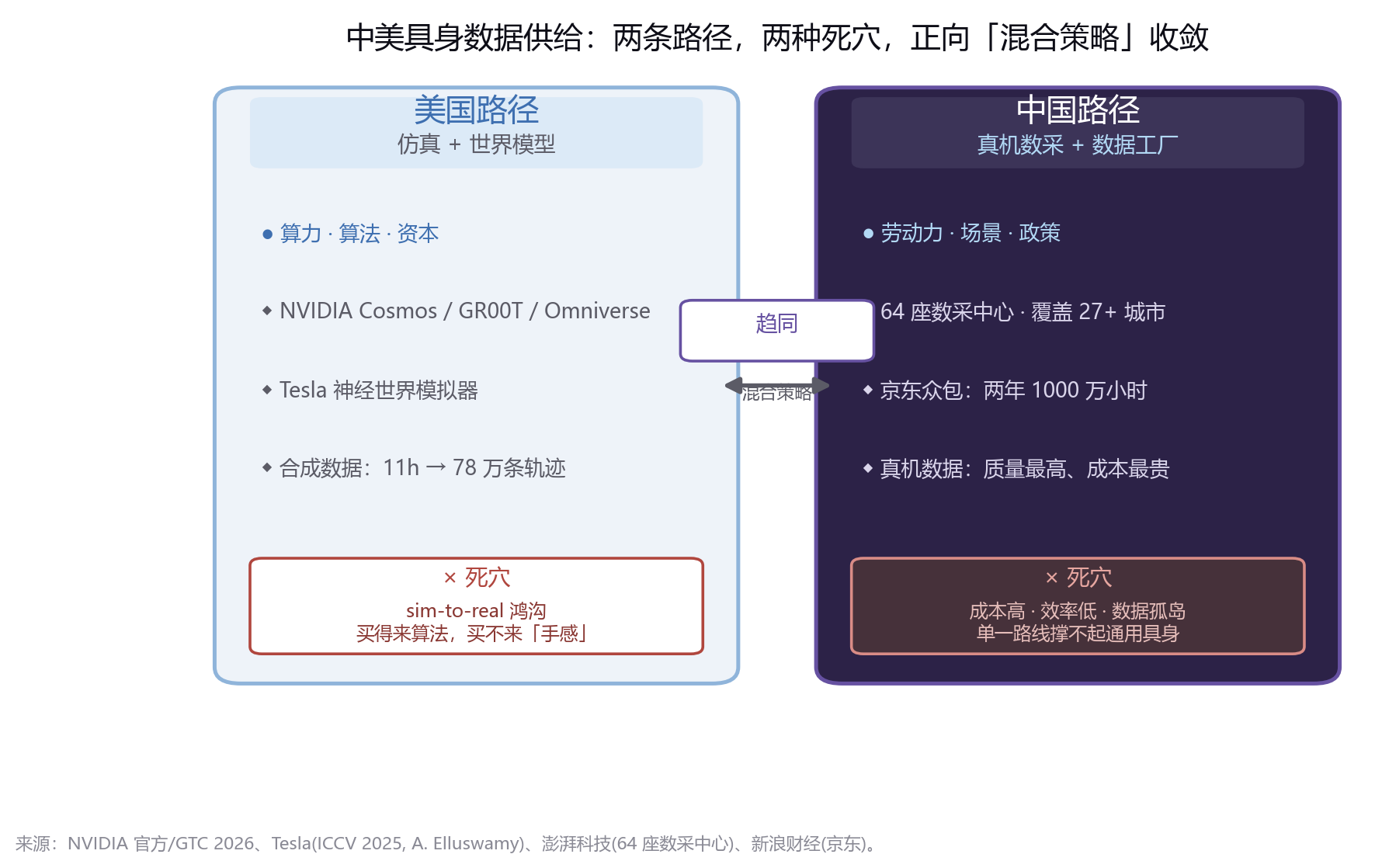
美国路径:仿真 + 世界模型,重算力、重算法、重资本。
NVIDIA 是这条路的总设计师。它用 Cosmos 世界基础模型、Isaac GR00T、Omniverse 仿真平台,搭起一座"数据工厂",本质是把算力转化为数据原料。Tesla 则走"本体即数据工厂"的垂直闭环——据其 AI 软件副总裁 Ashok Elluswamy 在 2025 年 10 月 ICCV 的披露,Optimus 与 FSD 共用同一个"神经世界模拟器",这是一种从真实世界视频中学习而来的"学习式仿真",可在雾天、暮光等不同条件下批量生成合成边缘案例。
美国阵营内部也有"真实数据派":Generalist AI 坚持用 27 万小时真机数据训练 GEN-0 基础模型,采集自全球数千个家庭、仓库与工作场所,每周新增超 1 万小时。
美国路径的死穴:sim-to-real 鸿沟。仿真环境的物理规律无法完全复现真实世界的复杂性,模型在仿真里表现优异、到真实场景却容易"翻车"。重算力买得来算法,却买不来真实世界的"手感"。
中国路径:真机数采 + 数据工厂,重劳动力、重场景、重政策。
中国把数采变成了一门"制造业"。截至 2026 年 4 月初,全国规划或建成的具身数采中心、创新中心与训练场已达 64 座、覆盖至少 27 个城市。智元在上海浦东建起 4000 平米专属工厂,日均产出数万条高质量数据;京东更计划两年内采集 100 万小时机器人本体数据 + 1000 万小时人类真实场景视频,发动数十万人众包采集。
政策是强力推手。具身智能连续两年写入相关政府工作报告;国家数据局推动"数据要素 ×"行动与数据资产入表;中国还首发了具身智能领域首份行业标准——《YD/T 6770—2026 人工智能 关键基础技术 具身智能基准测试方法》,已于2026 年 6 月 1 日正式实施。
中国路径的死穴:成本、效率与孤岛化。遥操作单小时有效数据成本仍在 500 元以上,一套设备超 20 万元,操作员门槛极高,真机数据很难快速规模化。更致命的是数据孤岛——跨本体、跨品牌的数据格式难以互通,任何一条单独的路线都撑不起通用具身智能的未来。
但请注意一个正在发生的趋同: 2026 年,双方都在向"混合策略"收敛。中国行业加速转向"强化中层仿真 + 夯实底层人类数据",以降低对昂贵真机数据的绝对依赖;美国的 Tesla、NVIDIA 也都强调真机 + 仿真 + 合成的多源融合。没有人押注单一数据源。
五、最危险的认知误区:被高估的"真实数据万能论"
讲到这里,必须给所有具身厂商泼一盆冷水:"真实数据一定优于合成数据",并不是一条已被证明的定律。
大语言模型的"GPT 时刻"建立在相对清晰的 Scaling Law 之上。但在机器人领域,数据的 Scaling Law 缺乏同等清晰的定义——"数据是否越多越好",本身就是一个需要实验验证的开放命题。
学术界的证据是混合的。清华团队的研究《模仿学习中的数据 Scaling Law》发现:环境与物体的多样性,远比单一环境下演示的绝对数量更重要——一旦每个环境/物体的演示量超过某个阈值,再增加演示,收效甚微。
但反方向的证据同样有力。Georgia Tech 与斯坦福的EgoMimic 研究(CoRL 2024)发现:用智能眼镜采集的人类第一人称(egocentric)数据,可使任务表现较纯机器人数据提升34%–228%;而且"2 小时机器人数据 + 1 小时人类手部数据"的组合,明显优于"3 小时纯机器人数据"。
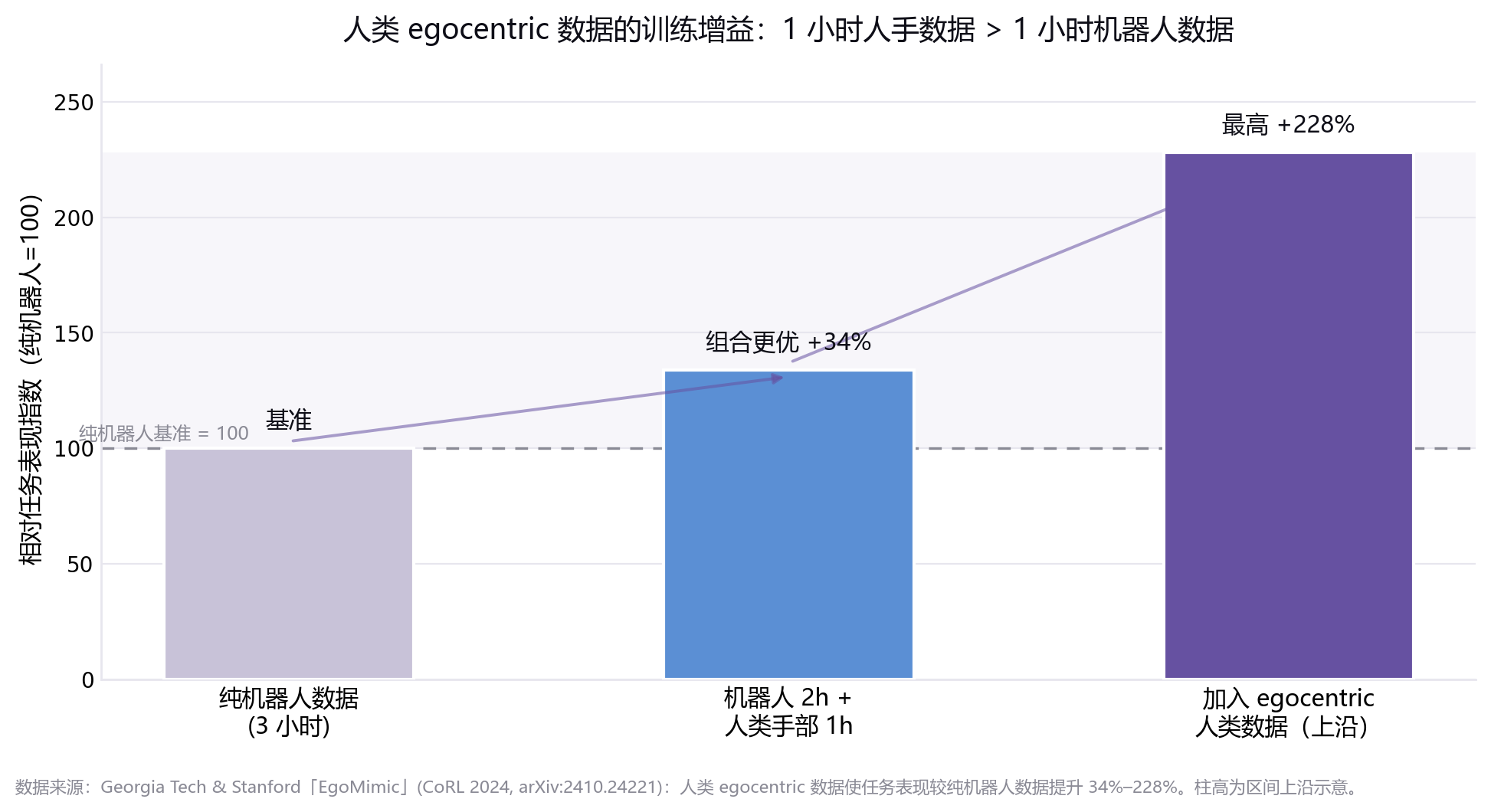
这意味着:真实数据(尤其是 egocentric 人类数据)的边际效用,是一个需要逐场景、逐任务实验验证的可测试假设,而非可以绝对化的营销口号。
真正决定模型能力上限的,从来不是"真实"或"合成"的标签,而是数据的——多样性、物理真实性、可评测性与合规性。
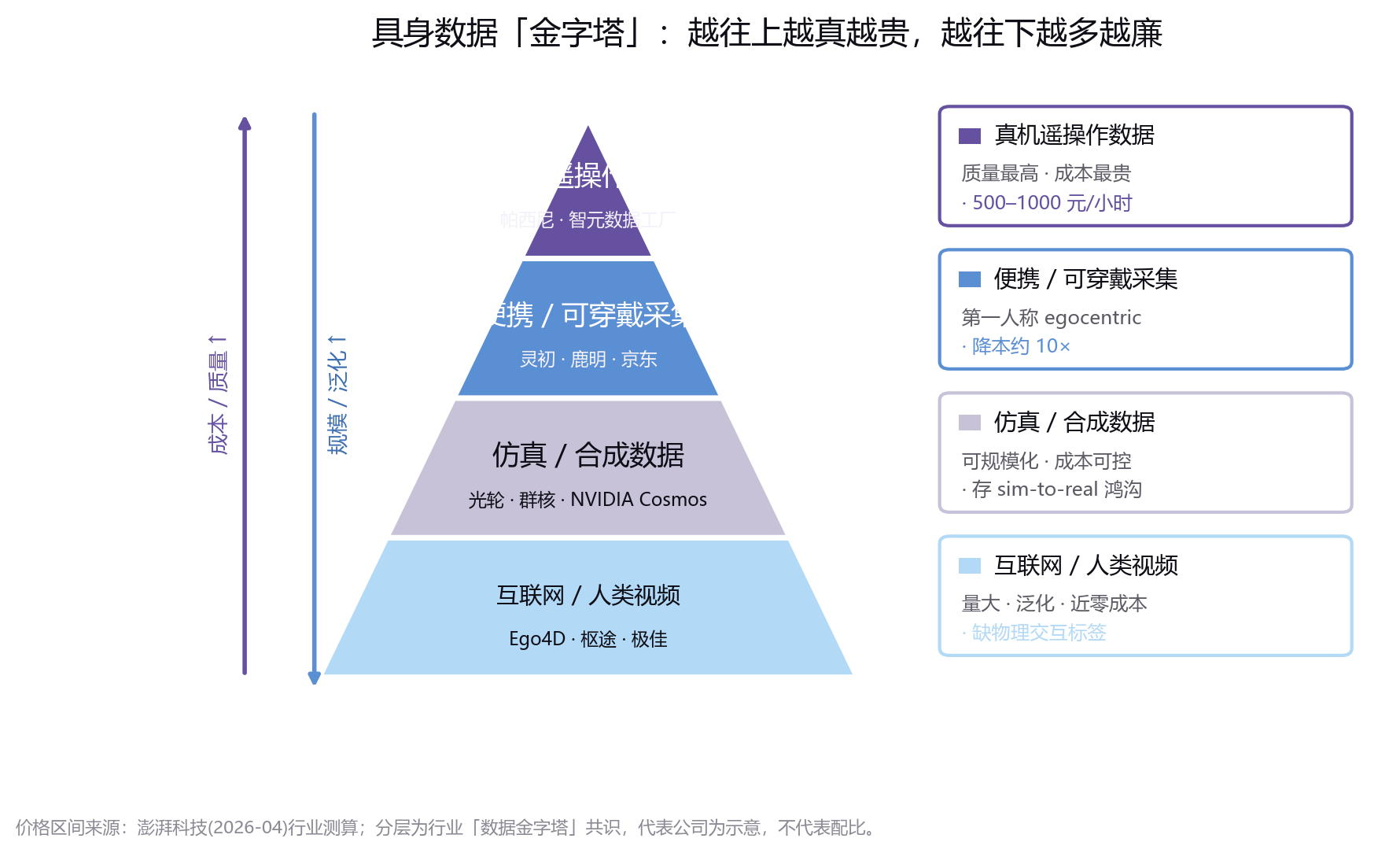
对厂商的启示因此清晰:与其盲目堆砌某一类数据,不如建立一套"持续、可迭代、可评测"的数据供给体系。按"金字塔"分层配置数据预算——底层用低成本人类视频夯实泛化,中层用仿真补足长尾,顶层用高质量真机攻坚精密操作——远比把任何一种数据奉为圭臬来得明智。
而这,恰恰是数据基础设施供给方的价值所在。
六、一个值得关注的样本:以"AI 垂类数据基础设施"切入价值链高位
在这场数据战争中,有一类"中立、合规、干净"的数据供给方正在浮现,艺恩数据(ENDATA,新三板代码 871430)是其中值得关注的样本。
需要先厘清的是:艺恩数据的传统主业是文娱垂类数据服务(影视、综艺、社媒内容的大数据分析)。而在 AI 数据基础设施的浪潮下,它正尝试把多年积累的"视频/图像/文本"三模态数据能力,向大模型与具身智能的训练数据延伸。这一延伸的逻辑,与本文的判断高度吻合。
其一,自有 egocentric 数据资产,踩中行业风口。据公司介绍,其储备了第一人称视角的 4D 数据集(公司自述规模 5PB、5000+ 小时,VLA-ready)。这一方向恰好与学界验证一致——前文 EgoMimic 已证明人类 egocentric 数据的高训练效率;Apple 的 EgoDex(829 小时 egocentric 视频、含桌面任务的 3D 手指追踪)、Tesla 转向头盔多摄采集第一人称视频,都在押注同一方向。
其二,合规与质量背书,是被低估的稀缺资产。这一点有一个绝佳的反面教材:2025 年 6 月,Meta 以约 143 亿美元入股数据标注巨头 Scale AI 近半股权,结果引发 Google、OpenAI 等客户因数据保密与竞争冲突而减少合作。这恰恰说明,"中立、不与客户竞争、合规干净"的第三方数据供给方,本身就是一种稀缺资产。艺恩强调的合规视频、干净 IP 链,正是大模型厂商最看重的护城河。
其三,清晰的战略分层,与行业"数据金字塔"共识吻合。据其对外阐述,它把具身数据价值链拆为三层:仿真层(最高价值/最高稀缺,长期竞争力)、渲染层(依托合规视频的当下现金牛)、规划层/VLA(随 VLA 模型爆发的 2026 增长重点)——这是一条"先做现金牛、再爬价值链"的务实路径。
需要特别强调的是:艺恩并不宣称真实数据绝对优于合成数据。恰恰相反,其立场与本文一致——真实数据的边际效用是一个需要实验验证的开放命题,而高质量、合规、egocentric 的真实数据资产,正是验证这一假设、并在混合数据策略中占据不可替代位置的关键变量。
七、给决策者的三步行动建议
如果你是具身机器人厂商的决策者,面对这场数据战争,建议分三步走。
第一步(立即):把数据预算从"附属投入"升级为"核心预算项",并按层分配。不要把全部预算压在最贵的真机遥操作上。采用"金字塔配置":底层用低成本人类 egocentric 视频与互联网视频夯实泛化,中层用仿真/合成数据规模化补足长尾,顶层用高质量真机数据攻坚精密操作。基准阈值——单一落地任务先确保千小时级有效数据,复杂任务按倍数追加。
第二步(3–6 个月):锁定合规、可评测、可跨本体复用的数据供给方,避免数据孤岛。优先选择具备合规认证、有干净 IP 链、能提供 VLA-ready 格式的供给方。对 egocentric/4D 数据资产给予额外权重——它在训练效率上已有实证优势,且不绑定特定本体。
第三步(持续):把"真实 vs 合成"当作可验证假设来管理,而非信仰。 在自有场景做 A/B 实验,量化每类数据的边际效用,动态调整配比。一个可操作的决策基准:若某类数据增加后模型成功率提升低于 5 个百分点,就该停止堆量、转向提升多样性或切换数据类型。
对中美路径的战略判断: 中国厂商的真机 + 场景优势,在工业、商超等"刚性场景"落地上短期领先,但务必同步布局仿真与人类视频数据,以对冲成本与孤岛风险;切忌迷信"采得多就赢"。
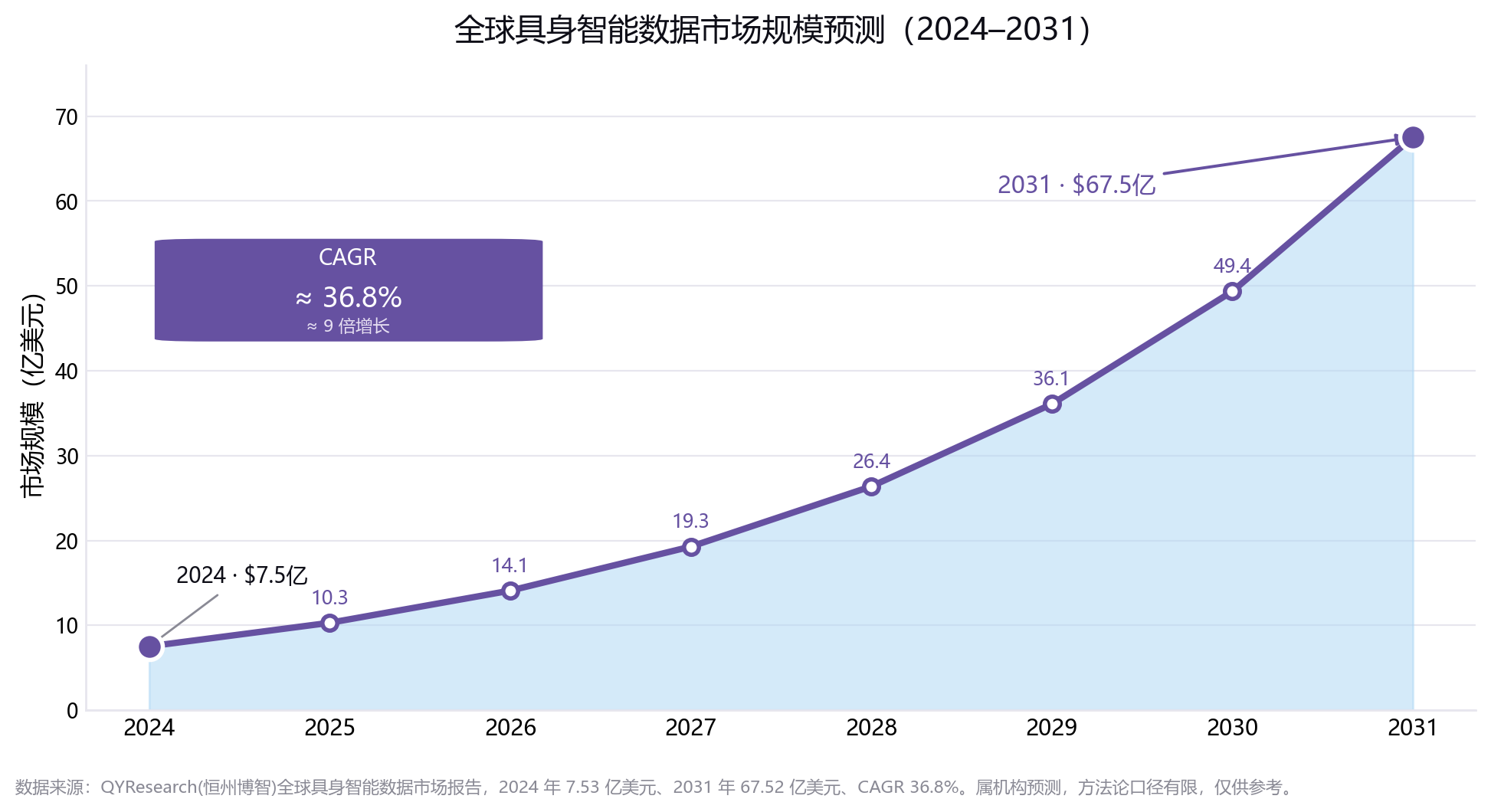
市场的大方向是确定的——据 QYResearch 预测,全球具身智能数据市场将从 2024 年的 7.53 亿美元增长到 2031 年的 67.52 亿美元,CAGR 约 36.8%。但在这条高速增长的赛道里,胜出的不会是采集数据最多的人,而是最先建成"持续、可迭代、可评测、合规"数据供给体系的人。
当 AI 从数字世界迈入物理世界,真实交互数据已成为决定具身智能上限的稀缺生产要素。读懂数据,就读懂了具身智能的下一程——这或许是这场全球竞赛,留给所有参与者最重要的一条共识。
- 人形机器人估值狂飙 390 亿美元,但闷声发财的是这群「卖铲人」
- QI Tech and Ant International’s Bettr Partner to Expand Credit Access for E-Commerce Merchants and C
- 玛氏M豆广州旗舰店盛大开业,打造沉浸式“豆”趣体验
- Ant International’s Alipay+ Kicks Off Joint Sustainability Initiatives with New York Liberty for 202
- 亿联网络升级新加坡全球运营总部 全新客户体验中心启用
- 哥斯达黎加电信监管局(SUTEL)部署Tecnotree平台以推进移动预付费注册的现代化并强化数字安全与信任
- TÜV莱茵与天消所达成战略合作 共筑消防产品出海新通道
- ExaGrid 在“存储奖”评选中斩获4项行业大奖
- Copeland发布2025财年全球影响力报告,重点展示能效、安全与创新方面的进展
- 2026年Esri用户大会将聚焦利用GIS创造更智能的世界